コンテンツの複製は、多数の問題を発生させます。
最大の問題は、検索者(お客様)への検索体験低下です。
具体的には、次の通りです。
「安倍首相 就任」等で検索します。
(数字は検索順位、表示サイトの例であり実際の結果ではありません)
1.ウィキペディア(安倍晋三の1ページ)
2.ウィキペディア(安倍晋三の2ページ目)
3.ウィキペディア(安倍晋三の1ページのモバイル版)
4.ウィキペディア(安倍晋三の1ページの英語版)
5.個人サイト(ウィキペディアへのlinkのみ)
6.個人サイト(ウィキペディアの丸コピー&体裁変更)
7.個人サイト(ウィキペディアの丸コピー&語尾変更)
みての通り、1~7は全て同じコンテンツです。
検索者が知りたいのは「クエリにマッチした多くの情報」です。
しかし、1~7が全て同じサイトの情報であれば、多様性が全く無く検索者は少ない情報しか得れません。
これは、Googleも排除したい内容です。
ということで最大の問題は、検索者に対する「検索体験の低下」です。
では、このことで「得」をする人は誰でしょうか?
5~7に関しては、殆ど労力を使うことなく、高品質なコンテンツを自サイトに取り込み、検索者を誘導しています。
なので、広告を設置するだけで、クリック収益が期待できます。
5~7は、自動巡回して自サイト内に自動作成するのも容易です。
7に関しては、オリジナルのコンテンツかどうかGoogleの判別を欺くような専用AIソフトも販売されています。
目次
では、今後どうなるのか、またサイト運営者はどうするのが良いか、というのをみてみたいと思います。
コンテンツの重複の種類
コンテンツの重複は非常に種類が多く全ては説明できませんが、例を基に説明してみます。
コンテンツ重複は次の問題で発生します。
①GoogleのCanonical(正規化)アルゴリズムが追いついていない
②運営者(ウェブマスター)の不備
③意図的な複製
④その他
この4つについて順番に説明してみます。
GoogleのCanonical(正規化)アルゴリズムが追いついていない
ご存じの方も多いと思いますが、Googleはこんな検索体験を低下させる検索結果を望んでいません。
なので、アルゴリズムによって自動対策を実施しています。
自動対策は2~7で自動的に発動します。
この、自動アルゴリズム(自動正規化:AutoCanonical)の機能は、重複コンテンツを検索結果に表示しない事です。
コンテンツを作ったのに公開されない=ペナルティだと思う方が殆どでしょう。
Googleは手動対策でさえ、ペナルティと呼んでいません。
私は、(このサイトでは)手動対策及び自動対策をペナルティと呼ぶことにします。
なので、自動正規化は、ペナルティと言っても過言ではありません。
自分が作成したコンテンツが公開されない=作成した労力が無になる
これは、制作者からみたら重大なペナルティでしょう。
さて、話しを戻します。
説明の通り2~7は、自動正規化され検索結果に表示されないようにGoogleは対策を実施してきます。
ただし、自動対策の中にも次の種類があります。
真のペナルティ
ペナルティのPで始まり白と黒をはっきりと付けるという意味のPandaアップデートです。
これらは、例の6~7が該当します。
通常は自動で検索結果から除外されますが、自動アルゴリズムがうまく機能しない場合は、手動対策としてウェブマスタに通知が行きます。
どのような内容かは、以下を確認願います。
無断複製されたコンテンツ
https://support.google.com/webmasters/answer/2721312
真のペナルティではない問題
2~4に関しては、非常に多い重複です。
主にウェブマスターのミスが原因ですが、Googleのバグによっても発生します。
詳細は次項で説明します。
運営者(ウェブマスター)の不備
この項では、ウェブマスターがタグを間違えたり、重複するコンテンツをインディックス要求するようなする場合です。
ページネーションのミス
2は、ページャーの問題です。
LinkタグでPrev/Nextがサポートされていたので、使用されている方も多いと思います。
しかし、これが問題を発生させる原因になることが多いです。
私は、/2/などサブページをインデックスするべきではないと一貫的に主張してきました。
その理由は、正規化アルゴリズムが間違ったページをインデックスするからです。
具体的な例を見てみましょう。
(現実のクエリではなく、あくまで例です)
例えば「はるか お菓子」で検索した場合
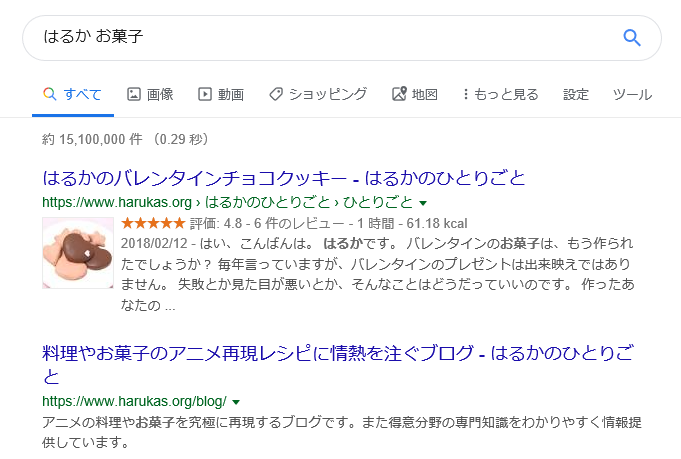
このような検索結果が正常だと仮定します。
クエリを少し変えたり、することによってGoogleは正規処理をミスすることがあり、次のような検索結果になることがあります。
正規化が正しく出来ていない検索結果
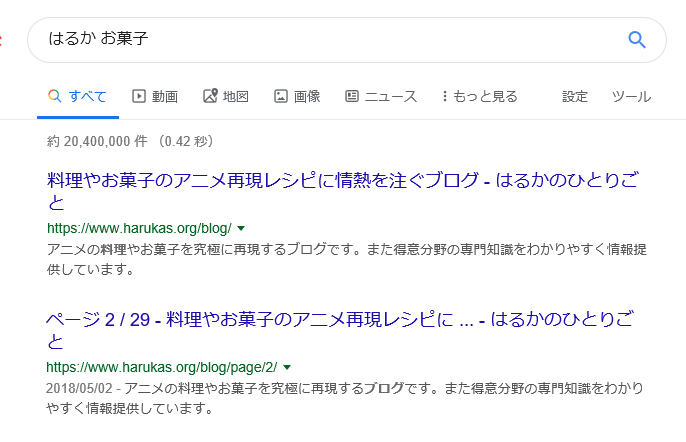
これは、1位2位とも全く同じページへジャンプする事になります。
Googleもウェブマスターも排除したい内容ですが、このような検索結果を表示する事があります。
prev/nextは既にインデックスシグナルではありません。
prev/nextを設置していても、Googleの自動正規化アルゴリズムの不備で、重複コンテンツが表示される場合があります。
このような価値のないページは、意図的に2ページ目以降をnoindexなどにする施策が重要です。
ただし、反対意見もあります。
まず前提です。
私は「記事」に関してnoindexは一切使うべきではないと主張します。
ですが「記事の一覧」については、日付archiveやcategoryarchiveなどで重複する場合が多数あります。
WordPressのテーマによっては、記事一覧が、10記事のコピーとか平気で存在します。
たとえば、ウェブマスター公式ブログです。(bloggerですがw)
ウェブマスター公式ブログのような設定は、使うべきではないと思います。
Googleが記事と、一覧を記事を正しく区別してくれればよいのですが、正規化アルゴリムズは、たまに「一覧をインディックスして、記事を表示しない」というとち狂った動きをする場合があります。
ウェブマスターフォーラムでも、この問題が何件も発生していました。
ウェブ制作者からみたら「作成した記事が検索結果に出ない」「ペナルティーだ」と叫ぶことになります。
慌てふためく前に、まず設定や送信しているサイトマップを再確認します。
キーワードに対して表示されるページは一意にしたいものです。
検索者の側に立ってみれば、記事一覧を「記事の連続コピー」などにするなんて狂気の沙汰です。
こういうのは、改善すべきでしょうね。
モバイルサイト実装のアノテーションミス
3に関しては、alternateの不備で発生する事が多いです。
a)タグが無い
→モバイル、PCに正しくタグを入れる。
動的な配信の場合、Vary HTTPヘッダーを使用してUAに応じた処理が必要です。
詳しくは、以下を参照してください。
モバイルサイトの構築
https://developers.google.com/webmasters/mobile-sites/?hl=ja
また、ウェブマスターフォーラムでよくあったのが
b)変なリダイレクト
これです。
海外だけブロックしていたりリダイレクトしたりしたりすると、Googlebotがサイト構造を正しく理解できません。
リダイレクトやブロックは細心の注意が必要です。
多言語実装のミス
4は、モバイルの実装ミスとほぼ同じです。
hreflangを正しく実装しましょう。
言語や地域の URL に hreflang を使用する
https://support.google.com/webmasters/answer/189077?hl=ja
ウェブマスターフォーラムで非常に多かったのが変なリダイレクトです。
IPが日本なら、日本語へリダイレクト、IPが米国なら英語へリダイレクト。
訪問者の事を思っての施策ですが、海外の利用者の意味が全く分かってないです。
アメリカ人が日本にやってきて、ローミングでdocomoからアクセスすると、日本のIPになります、そして日本語のページにリダイレクトします。
こんな事をすると、外国人は困りますよね。
ということで、変なリダイレクトはやめましょう。
また、リダイレクトはbotにも作用しますのでGooglebotも例外なくリダイレクトされちゃいます。
外国語実装したら、サイトが英語になりました!
というのの原因は、ほぼコレです。
どうしても言語を記憶したい場合は、訪問者に保存する言語を選択させるというのが最善だと思います。
具体的には、言語選択のボタンなどを準備しておき、選択された言語をクッキーに保存します。
すると以後はクッキーをみて最適な言語に転送できます。
Googlebotは、クッキーを使用しないので、変なリダイレクトも発生しません。
その他全般的な正規化ミス
正規化が出来ていなく、検索結果で不利な状況になっているものを説明します。
まず、Googleは以下の場合、全て別サイトあるいは別ページと認識します。
なので、必ず正規処理が必要です。
・HTTPS有無
httpとhttpsはプロトコルが違いますので、サイトが違うのと同義です。
通常両方のURLでインデックスできる状態の時HTTPS側を優先するのですが、被リンクの多い方を優先したりもして、どちらのURLも表示する事があります。
必ず、HTTPSへ301リダイレクトを行うように設定しましょう。
・www有無
wwwをサブドメインに付け、wwwサーバーだと明示しているウェブマスターも多いと思います。
しかし、wwwが付いているURLと付いていないURLは、全くの別サイトです。
必ず301リダイレクトを実施してください。
アルゴリズムでは、より単純なURLを優先する事が多く、wwwなしを優先するケースが多いように思います。
しかし、リンクがwwwの方が多かったらそうなりますし、やはり正しい正規化が必要です。
・/(スラッシュの有無)
スラッシュの扱いについて誤解が多いので整理します。
https://www.harukas.org
と
https://www.harukas.org/
は、Googleは全く同一のURLとして扱われます。
次に
https://www.harukas.org/blog
と
https://www.harukas.org/blog/
は、Googleは別のURLとして扱われます。
そうです。
サブディレクトリのみ、別のURLとして扱われるのですね。
このあたりはよく覚えておいてください。
また、大文字小文字は、linuxでは別に扱われますので、不用意に大文字を使わない様にした方が良いかと思います。
意図的な複製
これは、コピーしている人は、分かっている内容ですよね。
コピーされた側は、Googleに対して、スパム通報を行ってください。
DMCAも利用できますが、そんな事よりGoogleの自動/手動のペナルティに頑張ってもらいたいです。
私としては、Googleのスタンスも問題なのかと思います。
たとえばウェブマスターブログのように、「記事一覧を記事のコピー」にしているブログがあります。
こういったサイトに長山さんはオフィスアワーで「対策は不要」とはっきりと言っています。
まあ対策が必要ならこんな設定にはしないでしょうねw
この変なコピーサイトを、正しく処理しようとするので、正規化が難しくなっているのではないかと個人的には思います。
その他
今回、例に出し切れていないのも幾つかあります。
Googleアナリティクスを用い、サイトを解析する場合、各種パラメータを付ける事があります。
urlにパラメータを付けると付けないURLとば別のURLと判別される場合があります。
さらにECサイトでは、商品に応じた色のページなど、正常に運用してもいくつもの重複コンテンツが生成されます。
これらは、いくつ生成されても手動の対策が実施される事はありませんが、ウェブマスターが正しくタグを設置することにより、重複コンテンツを減らすことが可能です。
詳しくは、以下を参照してください。
重複するコンテンツ
https://support.google.com/webmasters/answer/66359?hl=ja
まとめ
今後は、自動正規化アルゴリズムが、どんどん高性能になっていくと思われます。
同時に誤動作も、起きないとも限りません。
まずは、インディックスの状態を確認し、正しくキーワードに応じた検索結果が表示されて居るのか、確認するのが良いでしょう。
また、自動/手動のコピーをしているサイトは、無意味になっていく可能性が高いです。
Googleを欺く手法で、収益をあげていても、必ず対策される日が来ます。
労力の無駄なので、そういった行為をせず、正攻法で行った方が良いかと思います。
記事を書いたとき、必ず重複コンテンツの確認が必要になります。
その手法を書いたので、以下を参照してみてください。
<追記>:既にFetchやinfo:が廃止されたので、おのおのインデックス送信とURL検査に読み替えてください。
重複コンテンツで、どうしてそう楽観できるのか信じられません。
1.記事を書く&Fetch
2.info:で記事URLでインディックスされている事の確認
3.site:自ドメイン <タゲクエリ>で希望の記事が出るか
重複が発生すると2,3が機能しません。
これらは当たり前の確認事項 pic.twitter.com/POOpljX6iX— はるか (@haruka_pigg) October 30, 2017

コメント